
I’ve spoken several times of hash-consing as a way to store contract data efficiently for the Tezos blockchain. Here’s why it’s useful, how it works, and what its limitations are.
Why it’s useful
Hash-consing in Tezos lets smart-contract seamlessly share data, with no duplication. If two smart contracts store the same table, they are only be stored once. If they store slightly different data, the overlap is also only stored once. This happens whenever two pieces of data are the same, even if by accident.
This has several benefits:
-
Many contracts are likely to implement sub-tokens, much like the famous “ERC20” contracts in Ethereum. Such contracts generally maintain a large map between public keys and amounts. Copying this map can be useful to create other tokens which start with the same allocation and then diverge. For example, the issuer of EggCoin can easily assign one EGG to every holder of ChickenCoin without duplicating any data.
-
Smart-contract code is also shared. A function used in many contracts is only stored once. There is no need to call into “library” contracts because any piece of code on the blockchain is implicitly a library!
-
A contract developer does not have to worry about the cost of serializing a large structure that’s been duplicated or passing large structures to other smart contracts. There is no costly copy of data.
How it works
Creating complex values
Michelson values are typed, and Michelson types are built from a few atomic types like int (arbitrary precision integers), string(character strings) timestamp(time-stamps), even signature (cryptographic signatures), and a few others.
We can combine those atomic types to build more complex types using constructors. For instance pair int string represents a pair of two value, an integer, and a string, or signature string represents a value that is either a signature or a string, list timestamp a list of time-stamps, and map key_hash nat is the type of an associative map between the hash of a public key and a positive integer.
It’s all binary trees
In the end, all of these complex structures can essentially be represented as binary trees. The leaves are atomic types, and intermediate nodes construct new types.
For instance, here’s a representation of the following structure. This is pair with a list of integers as its first element, and pair of string and timestamp as its second argument.
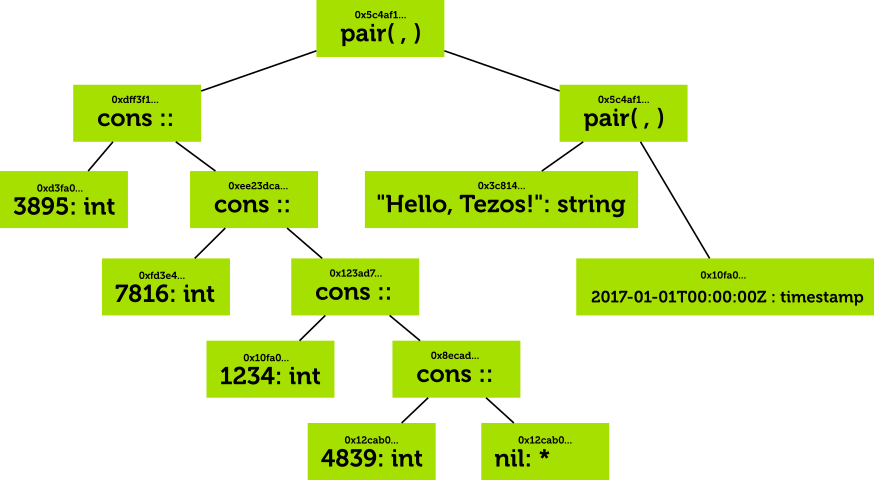 sample hash-consed value
sample hash-consed value
The list is built using the “cons” operator which prepends a value to a list, and a polymorphic nil value which represents the empty list.
Notice how each node and leaf in this tree has a hash. This lets us store this tree in a hash table:
 Structure represented in a hash table
Structure represented in a hash table
Notice how each entry represents a value, and how the hash of the entry reflects the whole content of that value.
Sharing data
Things become interesting once data becomes shared.
Suppose for instance that we wish to store a new value in our table, the list [3839; 7816; 1234; 3839]. This is almost the same as the list [1234; 7816; 1234; 3839] but the first element has been changed, and now matches the last element.
Here’s how the representation would look:
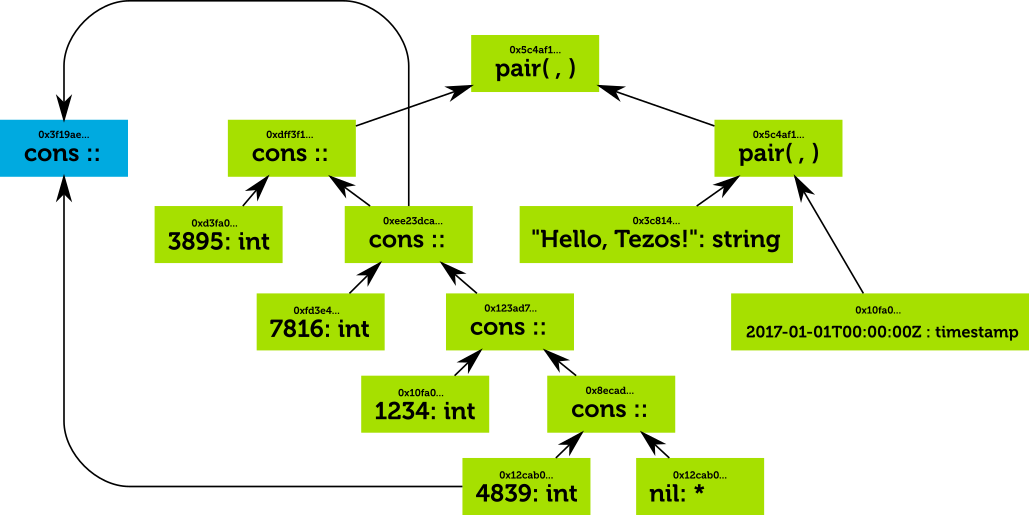 The new list is stored by simply adding a cons node
The new list is stored by simply adding a cons node
Note how the integer 4839 is only stored once, as is the tail of the list [7816;1234;4839]. This happens automatically because equal values are stored in the same spot in the hash-table. Our tree is no longer a tree, but a DAG.
Difficulties & workarounds
Overhead
Hash-consing introduces the overhead of a hash for every value it stores. Introducing a 160-bit hash to store a 64-bit integer introduces 250% of overhead! One way around this is to only apply hash consing to sub-trees above a certain size. For instance, if the hash is applied only to sub-trees larger than 1KB, the overhead becomes less than 2%.
Garbage collection
Suppose the contract storing the data that we described above changes the string “Hello, Tezos” to “Tezos, Rocks”. The new structure would look like this
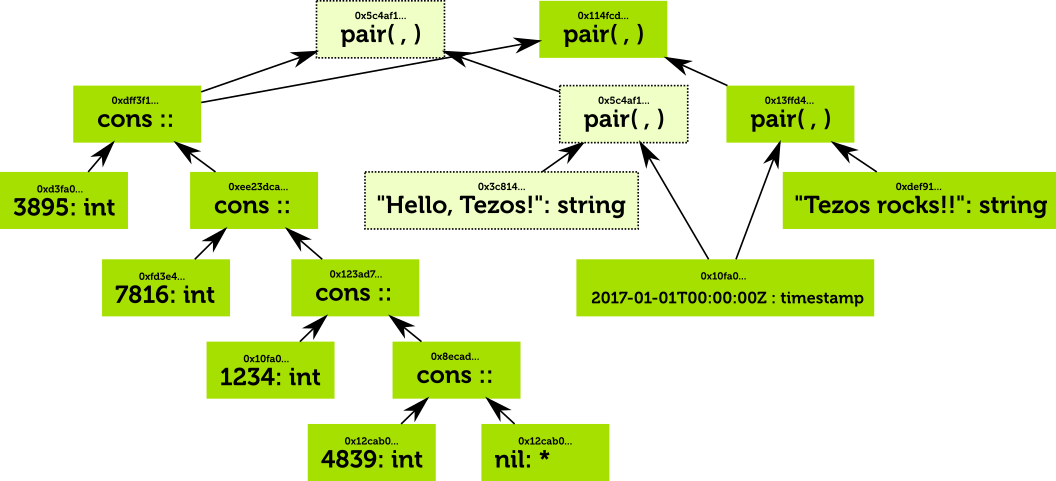 Changing “Hello, Tezos!” to “Tezos rocks!!”
Changing “Hello, Tezos!” to “Tezos rocks!!”
Most of the nodes in the tree are unchanged, but some nodes are now irrelevant (represented in light green) as they are not connected to the root of the tree.
Removing those nodes is called “garbage collection”. Fortunately, since we never form loops inside our data structure, we can use a very simple form of garbage collection called reference counting. Simply speaking, for each node, we keep track of how many other nodes it points to. If the counts falls to zero, and the node isn’t a top-level value in a smart-contract, the entire sub-tree can be deleted.
In total, garbage collection by reference counting will never take more time than it took to create the data in the first place. However, where things get tricky is that a data-structure built slowly over the course of many transactions could need to be garbage collected after a single transaction. This doesn’t work for a blockchain, as we want to strictly bound the time it takes to process a block.
The trick is thus to bound the amount of garbage collection performed at every block, and then resume, if needed, at the next block. It’s doable, but not trivial to implement correctly.
Sharing costs
Using up the state of the ledger represents a cost, who should pay for it and how?
One model is for every contract to hold a special balance proportional to the amount of space used. If a transaction increases the needed storage space, the additional storage cost can be extracted from the transaction fee.
In order to incentivize users to clean up unused data, it makes sense to refund the storage balance back to the contract creator if the contract is destroyed.
How does this model work in the presence of data sharing? If the data is shared, then copying it doesn’t really increase storage, and shouldn’t be costly, but destroying an instance of it doesn’t necessarily decrease storage.
A natural model for dealing with this is to share the fees. For instance, if Alice creates a piece of data X, she might put up 0.100 ꜩ for storage. Suppose now that Bob copies data X. He would put up 0.050 ꜩ for storage, and Alice would receive a refund of 0.050 ꜩ. There is still exactly 0.100 ꜩ committed to the storage of data X on the blockchain, but it’s now shared equally between Alice and Bob, who both stand to recover 0.050 ꜩ by deleting their data.
Unfortunately I haven’t yet found a way to perform this accounting efficiently. Suppose for instance that Alice creates a list [1;2;3;4;5;...;100000] and that Bob creates the integer 1000000 . The reference count on 1000000 increases by one, and it’s easy to immediately compute how much Bob should pay for the extra storage. However, in order to determine that Alice is eligible for a small refund, one would have to go backward through the list all the way to the first element. The alternative would be for every node in the storage to maintain pointers to every contract that references them, but that is extremely space inefficient: if N users store a common list of M elements, this would introduce N * M pointers!
Conclusion
Hash-consing will likely not be featured in the first version of Tezos, but I would like to see it in v2. An important unsolved issue is how to efficiently perform storage cost accounting.